Auf dieser Seite wird das Thema Komplexität behandelt.
Gegeben ist ein zu lösendes Problem. Es ist wünschenswert, dass der Algorithmus zur Berechnung der Lösung einen möglichst geringen Aufwand hat. Daher wird der Aufwand des Algorithmus (Komplexität) abgeschätzt . Zur Lösung von Problemen einer bestimmten Klasse gibt es einen Mindestaufwand.
Motivierendes Beispiel[Bearbeiten]
Als Beispiel nutzen wir die sequentielle Suche in Folgen.
Gegeben ist die Zahl b und n Zahlen, z.B. mit A[0...n-1] mit n>0, wobei die Zahlen verschieden sind. Gesucht ist ein Index ![{\displaystyle i\in \{0,...,n-1\}~mit~b=A[i]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1a71db61f40cc4120f56376913b0d03b8d4bc95a) , falls der Index existiert, sonst ist i = n.
Die Lösung für das Problem ist:
, falls der Index existiert, sonst ist i = n.
Die Lösung für das Problem ist:
i = 0;
while (i < n && b != A[i])
i++;
Der Aufwand der Suche hängt nun von der Eingabe ab, d.h vom gewählten Wert n, den Zahlen A[0],...,A[n] und von b. Es gibt zwei Möglichkeiten, eine erfolgreiche oder eine erfolglose Suche. Eine erfolgreiche Suche haben wir, wenn b=A[i] dann ist S=i+1 Schritte. Ist die Suche jedoch erfolglos, dann ist S=n+1 Schritte. Das Problem ist, dass die Aussage von zu vielen Parametern abhängt und unser Ziel ist eine globale Aussage zu finden, die nur von einer einfachen Größe abhängt, z.B. der Länge n der Folge.
Analyse erfolgreiche Suche[Bearbeiten]
Im schlechtesten Fall wird b erst im letzten Schritt gefunden, d.h. b=A[n-1]. Dann wäre S=n.
Im Mittel wird die Anwendung mit verschiedenen Eingaben wiederholt. Wenn man beobachtet wie oft b an erster, zweiter,..., letzter Stelle gefunden wird, hat man eine Annahme über die Häufigkeit. Läuft der Algorithmus k mal (k>1), so wird b gleich oft an erster, zweiter,....,letzter Stelle gefunden und somit k/n mal an jeder Stelle.
Die Anzahl der Schritte insgesamt für k Suchvorgänge lässt sich folgendermaßen berechnen:




Für eine Suche benötigt man  Schritte
Daraus folgt, dass im Mittel ( bei einer Gleichverteilung)
Schritte
Daraus folgt, dass im Mittel ( bei einer Gleichverteilung) 
Asymptotische Analyse[Bearbeiten]
Zur Analyse der Komplexität geben wir eine Funktion als Maß für den Aufwand an.  . Das bedeutet f(n)=a bei Problemen der Größe n beträgt der Aufwand a. Die Problemgröße ist der Umfang der Eingabe, wie z.B. die Anzahl der zu sortierenden oder zu durchsuchenden Elemente. Der Aufwand ist die Rechenzeit( Abschätzung der Anzahl der Operationen, wie z.B. Vergleiche) und der Speicherplatz.
. Das bedeutet f(n)=a bei Problemen der Größe n beträgt der Aufwand a. Die Problemgröße ist der Umfang der Eingabe, wie z.B. die Anzahl der zu sortierenden oder zu durchsuchenden Elemente. Der Aufwand ist die Rechenzeit( Abschätzung der Anzahl der Operationen, wie z.B. Vergleiche) und der Speicherplatz.
Aufwand für Schleifen[Bearbeiten]
Wie oft wird die Wertezuweisung x=x+1 in folgenden Anweisungen ausgeführt?
1-mal
for (i = 1; i <= n; i++)
x = x + 1;
n-mal
for (i = 1; i <= n; i++)
for (j = 1; j <= n; j++)
x = x + 1;
 -mal
-mal
Die Aufwandsfunktion ist meist nicht exakt bestimmbar. Daher wird der Aufwand im schlechtesten Fall und im mittleren Fall abgeschätzt und die Größenordnung ungefähr errechnet.
Vergleich Größenordnung[Bearbeiten]
| Funktion |
n=100 |
n=10.000 |
n=100.000
|
| log n |
4,6 |
9,2 |
11,5
|
|
10.000 |
100.000.000 |
10.000.000.000
|
 |
1.000.000 |
 |

|
Wie können wir das Wachstum von Funktionen abschätzen und wie verhalten sich die Funktionen zueinander?
Das Ziel ist, die Funktion  zu wählen, die
zu wählen, die  nach oben beschränkt.
nach oben beschränkt.





Da die Vorlesungsinhalte auf dem Buch Algorithmen und Datenstrukturen: Eine Einführung mit Java von Gunter Saake und Kai-Uwe Sattler aufbauen, empfiehlt sich dieses Buch um das hier vorgestellte Wissen zu vertiefen. Die auf dieser Seite behandelten Inhalte sind in Kapitel 7.3 zu finden.
Auf dieser Seite wird die O-Notation behandelt.
Bei der O-Notation werden die asymptotischen oberen Schranke für Aufwandsfunktion angegeben. Das heißt deren Wachstumsgeschwindigkeit bzw. Größenordnung.
Eine Asymptote ist eine Gerade, der sich eine Kurve bei immer größer werdender Entfernung vom Koordinatenursprung unbegrenzt nähert. Eine einfache Vergleichsfunktion ist  für Aufwandsfunktionen mit
für Aufwandsfunktionen mit 
Für eine Funktion ist die Menge  wie folgt definiert:
wie folgt definiert:

Anschaulich formuliert bedeutet das, dass O(f(n)) die Menge aller durch f nach oben beschränkter Funktionen ist und somit die asymptotische obere Schranke ist.
Die Definition veranschaulichst sieht folgendermaßen aus:

Das heißt g wächst nicht schneller als f. Das bedeutet wiederrum  ist für genügend große n durch eine Konstante c nach oben beschränkt.
ist für genügend große n durch eine Konstante c nach oben beschränkt.
Da die Vorlesungsinhalte auf dem Buch Algorithmen und Datenstrukturen: Eine Einführung mit Java von Gunter Saake und Kai-Uwe Sattler aufbauen, empfiehlt sich dieses Buch um das hier vorgestellte Wissen zu vertiefen. Die auf dieser Seite behandelten Inhalte sind in Kapitel 7.3.2 zu finden.
 -Notation[Bearbeiten]
-Notation[Bearbeiten]
Für eine Funktion ist die Menge  wie folgt definiert:
wie folgt definiert:

Anschaulich formuliert bedeutet das, dass die Menge aller durch f nach unten beschränkter Funktionen ist und somit die asymptotische untere Schranke ist.
 -Notation[Bearbeiten]
-Notation[Bearbeiten]
Die exakte Ordnung von f(n) ist definiert als:

Oder etwas kompakter:

Anschaulich formuliert bedeutet das, dass die Menge aller durch f nach unten und oben beschränkter Funktionen und somit die asymptotische untere und obere Schranke ist.
Zu zeigen:


Zeige 




Wir stellen uns die Frage, ob  bzw. ob eine obere Schranke für ist. Die Antwort ist ja. Die Begründung dazu lautet folgendermaßen:
bzw. ob eine obere Schranke für ist. Die Antwort ist ja. Die Begründung dazu lautet folgendermaßen:



Wir stellen uns die Frage, ob  bzw. ob eine obere Schranke für ist. Die Antwort ist nein. Beweisen kann man das durch Widerspruch.
Unsere Annahme ist:
bzw. ob eine obere Schranke für ist. Die Antwort ist nein. Beweisen kann man das durch Widerspruch.
Unsere Annahme ist:



Wähle  Widerspruch!!
Widerspruch!!
Für beliebige Funktionen f,g gilt:

Beweis in beide Richtungen[Bearbeiten]


Als erstes machen wir den Beweis nach rechts ( )
)



nun der Beweis nach links ( )
)






1.  2.
2.  3.
3. 
Beweis in beide Richtungen[Bearbeiten]
Beweis zu 1. nach rechts ()


Beweis zu 1. nach links ()

 (siehe Definition)
(siehe Definition)
und sei t(n) ein beliebiges Element der Menge O(f(n))
 (siehe Definition)
(siehe Definition)


 (Definition der Teilmenge, da t(n) ein beliebiges Element ist)
(Definition der Teilmenge, da t(n) ein beliebiges Element ist)

Damit ist



Damit ist


Damit ist

Falls  , dann ist auch
, dann ist auch  .
.



Dabei ist  eine Konstante.
eine Konstante.




1.  2.
2. 
Ein häufiges Problem sind Grenzwerte der Art  oder
oder  Bei diesem Problem kann man als Ansatz die Regel von de l'Hospital verwenden.
Bei diesem Problem kann man als Ansatz die Regel von de l'Hospital verwenden.
Satz(Regel von de L'Hospital)  Seien f und g auf dem Intervall
Seien f und g auf dem Intervall  differenzierbar.
Es gelte
differenzierbar.
Es gelte  und es existiere
und es existiere  .
Dann existiert auch
.
Dann existiert auch  und es gilt:
und es gilt:

1. 

2. 

Beim zweiten Beispiel musste die Regel von de l'Hospital wiederholt angewandt werden.
Gibt es immer eine Ordnung zwischen den Funktionen? Es gibt Funktionen f und g mit  . Ein Beispiel sind die Funktionen sin(n) und cos(n).
. Ein Beispiel sind die Funktionen sin(n) und cos(n).
Für alle 
Beweis durch Widerspruch[Bearbeiten]
Wir nehmen an, dass  ,
,
das heißt  .
.
Aber es muss auch  gelten,
gelten,
das heißt 

Komplexitätsklassen[Bearbeiten]
Auf dieser Seite werden die Komplexitätsklassen behandelt.
Wir sagen sei  Und wir sagen, ein Algorithmus mit Komplexität f(n) benötigt höchstens polynomielle Rechenzeit, falls es ein Polynom p(n) gibt, mit
Und wir sagen, ein Algorithmus mit Komplexität f(n) benötigt höchstens polynomielle Rechenzeit, falls es ein Polynom p(n) gibt, mit  .
Des weiteren sagen wir, dass ein Algorithmus höchstens exponentielle Rechenzeit benötigt, falls es eine Konstante
.
Des weiteren sagen wir, dass ein Algorithmus höchstens exponentielle Rechenzeit benötigt, falls es eine Konstante  gibt, mit
gibt, mit  .
.
Die Komplexitätsklassen sind:
 |
der konstante Aufwand, das bedeutet der Aufwand ist nicht abhängig von der Eingabe
|
 |
der logarithmische Aufwand
|
 |
der lineare Aufwand
|
 |
|
 |
der quadratische Aufwand
|
 |
der polynomiale Aufwand
|
 |
der exponentielle Aufwand
|
| f(n) |
n=2 |
 |
 |
 |

|
| ldn |
1 |
4 |
8 |
10 |
20
|
| n |
2 |
16 |
256 |
1024 |
1048576
|
 |
2 |
64 |
2048 |
10240 |
20971520
|
|
4 |
256 |
65536 |
1048576 |

|
|
8 |
4096 |
16777200 |
 |

|
 |
4 |
65536 |
 |
 |

|
Nun stellen wir uns die Frage, wie groß bezüglich der Rechenschritte darf, oder kann ein Problem sein, je nach Komplexitätsklasse, wenn die Zeit T begrenzt ist? Wir nehmen an, dass wir pro Schritt eine Rechenzeit von  brauchen.
In der folgenden Tabelle steht T für die Zeitbegrenzung und G für die maximale Problemgröße.
brauchen.
In der folgenden Tabelle steht T für die Zeitbegrenzung und G für die maximale Problemgröße.
| G |
T=1Min. |
1 Std. |
1 Tag |
1 Woche |
1 Jahr
|
| n |
 |
 |
 |
 |

|
|
7750 |
 |
 |
 |

|
|
391 |
1530 |
4420 |
8450 |
31600
|
|
25 |
31 |
36 |
39 |
44
|
Ein Beispiel ist für T=1 Min. : 
Typische Problemklassen[Bearbeiten]
| Aufwand |
Problemklasse
|
|
für einige Suchverfahren für Tabellen (Hashing)
|
|
für allgemeine Suchverfahren für Tabellen (Baum-Suchverfahren)
|
|
für sequenzielle Suche, Suche in Texten, syntaktische Analyse von Programmen (bei "guter" Grammatik)
|
|
für Sortieren
|
|
für einige dynamische Optimierungsverfahren (z.B. optimale Suchbäume), einfache Multiplikation von Matrix-Vektor
|
 |
für einfache Matrizen Multiplikationen
|
|
für viele Optimierungsprobleme (z.B. optimale Schaltwerke), automatisches Beweisen (im Prädikatenkalkül 1.Stufe)
|
Da die Vorlesungsinhalte auf dem Buch Algorithmen und Datenstrukturen: Eine Einführung mit Java von Gunter Saake und Kai-Uwe Sattler aufbauen, empfiehlt sich dieses Buch um das hier vorgestellte Wissen zu vertiefen. Die auf dieser Seite behandelten Inhalte sind in Kapitel 7.3.3 zu finden.
Aufwandsanalyse von iterativen Algorithmen[Bearbeiten]
Auf dieser Seite wird der Aufwand von iterativen Algorithmen analysiert.
Als Aufwand wird die Anzahl der durchlaufenen Operationen zur Lösung des Problems bezeichnet ( Zuweisungen, Vergleiche...). Häufig ist der Aufwand abhängig vom Eingabeparameter (Problemgröße). Die Aufwandsklasse sagt, wie der Aufwand in Abhängigkeit von der Problemgröße wächst. Doch wie kann man nun bei beliebigem Java Code die Aufwandsklasse bestimmen?
Aufwand von Programmen ablesen[Bearbeiten]
void alg1(int n){
int m = 2;
int i;
int k = n;
while (n > 0){
i = k;
while (i > 0) {
m = m + i;
i = i / 2;
}
n = n - 1;
}
}
Die Aufwandsklasse ist . Die äußere Schleife wird n-mal durchlaufen und die Innere Schleife log n-mal.
void alg1(int n) {
int m = 1;
int i = 0;
while (m < n) {
while (i < m)
i = i + 1;
m = m + i;
}
}
Hier ist die Aufwandsklasse O(n+log n). In jedem Durchlauf der äußeren Schleife wird m verdoppelt, d.h. sie läuft log n Mal. Die innere Schleife läuft bis n/2, aber nicht jedes Mal, weil i nur ein Mal auf 0 gesetzt wird. Man könnte als Aufwandsklasse auch O(n) sagen, da der Summand log n nicht ins Gewicht fällt.
Bestandteile iterativer Algorithmen[Bearbeiten]
Zum einen haben wir elementare Anweisungen wie Zuweisungen und Vergleiche. Diese haben einen Aufwand von 1.
Des Weiteren haben wir Sequenzen  oder auch
oder auch  geschrieben. Die obere Grenze ist
geschrieben. Die obere Grenze ist  und die untere Grenze ist
und die untere Grenze ist  . Dabei ist
. Dabei ist  der Aufwand, der bei der Ausführung von
der Aufwand, der bei der Ausführung von  entsteht.
entsteht.
Ein weiterer Bestandteil ist die Selektion.  . Hier ist die obere Grenze
. Hier ist die obere Grenze  und die untere Grenze
und die untere Grenze  .
.
Außerdem haben wir Iterationen  . Hierbei ist die obere und die untere Grenze die Anzahl der Schleifendurchläufe,
. Hierbei ist die obere und die untere Grenze die Anzahl der Schleifendurchläufe,  und die untere Grenze
und die untere Grenze  . Doch wie ist der Aufwand für eine for-Schleife? Ein Beispiel ist
. Doch wie ist der Aufwand für eine for-Schleife? Ein Beispiel ist  . Die Antwort ist die Abbildung auf eine while-Schleife.
. Die Antwort ist die Abbildung auf eine while-Schleife.

while(B) {


}
public int berechne(int n) {
int x = 0;
x = x + 1;
return x;
}
Jede Zeile hat den Aufwand  . Wie viele Operationen werden nun durchlaufen? Und ist die Anzahl abhängig vom Eingabeparameter?
Der Aufwand ist
. Wie viele Operationen werden nun durchlaufen? Und ist die Anzahl abhängig vom Eingabeparameter?
Der Aufwand ist 
Die Aufwandsklasse ist somit 
public int berechne(int n) {
int x = 0;
for (int i=0; i < n; i++) {
x = x + 1;
}
return x;
}
Die for Schleife hat den Aufwand  . Die Initialisierung und das return haben jeweils den Aufwand .
. Die Initialisierung und das return haben jeweils den Aufwand .
Der Gesamtaufwand ist somit  . Somit ist die Aufwandsklasse
. Somit ist die Aufwandsklasse  .
.
public int berechne(int n) {
int x = 0;
for (int i=0; i < n; i++) {
for (int j=0; j < n; j++) {
x = x + 1;
}
}
return x;
}
Hier hat die for-Schleife den Aufwand  und die Initialisierung und das return wieder . Damit ergibt der sich Gesamtaufwand
und die Initialisierung und das return wieder . Damit ergibt der sich Gesamtaufwand  . Daraus folgt die Aufwandsklasse
. Daraus folgt die Aufwandsklasse  .
.
public int berechne(int n) {
if (n % 2 == 0) {
int x = 0;
for (int i=0; i < n; i++) {
x = x + 1;
}
return x;
}else{
return n;
}
}
Hier hat die for-Schleife einen Aufwand von  . Die Initialisierung und das return wieder .
. Die Initialisierung und das return wieder .
Die obere Grenze ist somit  und die untere Grenze
und die untere Grenze 
Zu den häufig verwendeten Faustregeln gehört, dass wenn wir keine Schleife haben, der Aufwand konstant ist. Eine weitere ist, dass bei einer Schleife immer ein linearer Aufwand vorliegt. Bei zwei geschachtelten Schleifen haben wir immer einen quadratischen Aufwand. Doch die Faustegeln gelten nicht ohne Ausnahmen. Besonders Acht geben muss man bei Aufwandsbestimmungen für Schleifen, bei mehreren Eingabevariablen, bei Funktionsaufrufen und bei Rekursionen.
Aufwandsbestimmung für Schleifen[Bearbeiten]
public int berechne(int n) {
int x = 0;
for (int i=0; i < 5; i++) {
x = x + 1;
}
return x;
}
Der Schleifenabbruch hängt nicht vom Eingabeparameter ab. Der Aufwand beträgt  somit haben wir die Aufwandsklasse
somit haben wir die Aufwandsklasse 
public int berechne(int n) {
int x = 0;
for (int i=1; i < n; i = 2*i) {
x = x + 1;
}
return x;
}
Hier wächst die Laufvariable nicht linear an.Daher ist der Aufwand  und wir haben die Aufwandsklasse
und wir haben die Aufwandsklasse  .
.
Doch gibt es eine allgemeine Methodik zum Bestimmen des Schleifenaufwands?
for (int i=1; i < n; i=2*i) {
x = x + 1;
}
Schritt 1: Wie entwickelt sich hier die Laufvariable? Der Startwert i ist 1 und die Veränderung in jedem Schritt ist  . Die Laufvariable entwickelt sich somit wie folgt:
. Die Laufvariable entwickelt sich somit wie folgt:
Nach dem 1. Durchlauf 
Nach dem 2. Durchlauf 
Nach dem 3. Durchlauf 
Nach dem k. Durchlauf 
Schritt 2: Nach wie vielen Durchläufen wird die Schleife abgebrochen?
Der Abbruch erfolgt, wenn 
:


Somit erfolgt ein Abbruch nach  ⌈
⌈  ⌉ Durchläufen.
⌉ Durchläufen.
public int berechne(int[] f1, int[] f2) {
int result = 0;
for (int i=0; i < f1.length; i++) {
for (int j=0; j < f2.length; j++) {
if (f1[i] == f2[j]) result++;
}
}
return result;
}
Hier haben wir nun eine for Schleife mit mehreren Eingabevariablen. Die Problemgrößen sind  .
.
public int berechne2(int[] f1, int[] f2){
f2 = mergeSort(f2);
int result = 0;
for (int i=0; i < f1.length; i++) {
if (binarySearch(f2, f1[i])) result++;
}
return result;
}
Der Aufwand ist hier  . Somit ist die Aufwandsklasse
. Somit ist die Aufwandsklasse  .
.
In diesem Beispiel haben wir wieder mehreren Eingabevariablen. Diese sind die gleichen Problemgrößen .
public int berechne2(int[] f1, int[] f2){
int result = 0;
for (int i=0; i < f1.length; i++) {
for (int j=0; j < f2.length; j++) {
if (f1[i] == f2[j]) result++;
}
}
return result;
}
Der Aufwand ist hier wie folgt:  . Somit ist die Aufwandsklasse
. Somit ist die Aufwandsklasse  .
.
Da die Vorlesungsinhalte auf dem Buch Algorithmen und Datenstrukturen: Eine Einführung mit Java von Gunter Saake und Kai-Uwe Sattler aufbauen, empfiehlt sich dieses Buch um das hier vorgestellte Wissen zu vertiefen. Die auf dieser Seite behandelten Inhalte sind in Kapitel 7.3.4 zu finden.
Aufwandsanalyse von rekursiven Algorithmen[Bearbeiten]
Auf dieser Seite wird der Aufwand von rekursiven Algorithmen untersucht.
public int fib(int n) {
if (n == 0 || n == 1) {
return 1;
} else {
return fib(n-1) + fib(n-2);
}
}
Wie ist nun der Aufwand für Fibonacci? Bei Rekursionsabbruch  und im Rekursionsfall
und im Rekursionsfall  . Zur Bestimmung benutzen wir Rekursionsgleichungen.
. Zur Bestimmung benutzen wir Rekursionsgleichungen.
Rekursionsgleichungen[Bearbeiten]
Eine Rekursionsgleichung ist eine Gleichung oder Ungleichung, die eine Funktion anhand ihrer Anwendung auf kleinere Werte beschreibt.
Rekursionsgleichung für Fibonacci:

Lösung von Rekursionsgleichungen[Bearbeiten]
Die Frage ist nun, welche Aufwandklasse T(n) beschreibt. Dies könnten alle möglichen Aufwandsklassen sein. Methoden um dieses Problem zu lösen, sind die vollständige Induktion und das Master-Theorem.
Spezialfall Divide and Conquer Algorithmus[Bearbeiten]
Ein Divide-and-Conquer Algorithmus stellt im Allgemeinen eine einfache, rekursive Version eines Algorithmus dar und hat drei Schritte:
- Divide: Unterteile das Problem in eine Zahl von Teilproblemen
- Conquer: Löse das Teilproblem rekursiv. Wenn das
Teilproblem klein genug ist, dann löse das Teilproblem direkt (z.B. bei leeren oder einelementigen Listen)
- Combine: Die Lösungen der Teilprobleme werden zu einer Gesamtlösung kombiniert.
Merge Sort ist beispielsweise ein Divide and Conquer Algorithmus.
- Divide: Zerteile eine Folge mit n Elementen in zwei Folgen mit je n/2 Elementen.
- Conquer: Wenn die resultierende Folge 1 oder 0 Elemente enthält, dann ist sie sortiert.Ansonsten wende Merge Sort rekursiv an.
- Combine: Mische die zwei sortierten Teilfolgen.
public List mergeSort(List f) {
if (f.size() <= 1) {
return f;
} else {
int m = f.size() / 2;
List left = mergeSort(f.subList(0,m));
List right = mergeSort(f.subList(m,f.size());
return merge(left, right);
}
}
Die dazugehörige Rekursionsgleichung lautet:

Im Allgemeinen ist die Rekursionsgleichung für Divide and Conquer Algorithmen:

mit D(n) als Aufwand für Divide, T(n/b) als Aufwand für Conquer und C(n) als Aufwand für Combine.
Die Rekursionsgleichung von MergeSort beschreibt den Aufwand für den schlechtesten Fall.

Aber die Annahme, dass n eine geeignete ganze Zahl ist ergibt normalerweise das gleiche Ergebnis wie
eine beliebige Zahl mit Auf- bzw. Abrunden. Dies führt zur einfacheren Rekursionsgleichung:
Beispiel Binäre Suche[Bearbeiten]
public List binarySearch(ArrayList<Integer> f, int e) {
if (f.size() == 0) {
return -1;
} else {
int m = f.size() / 2;
if (f.get(m) == e) {
return m;
} else if (f.get(m) < e) {
return binarySearch(f.subList(0, m), e);
} else {
return binarySearch(f.subList(m+1, f.size()), e);
}
}
}
Die Rekursionsgleichung lautet

Da die Vorlesungsinhalte auf dem Buch Algorithmen und Datenstrukturen: Eine Einführung mit Java von Gunter Saake und Kai-Uwe Sattler aufbauen, empfiehlt sich dieses Buch um das hier vorgestellte Wissen zu vertiefen. Die auf dieser Seite behandelten Inhalte sind in Kapitel 7.3.4 zu finden.
Vollständige Induktion[Bearbeiten]
Auf dieser Seite wird die vollständige Induktion behandelt. Es handelt sich hierbei um eine rekursive Beweistechnik aus der Mathematik. Sie ist gut geeignet, um Eigenschaften von rekursiv definierten Funktionen zu beweisen.
Zunächst vermutet man eine Eigenschaft (z.B. Aufwandsklasse einer Rekursionsgleichung). Nun folgt der Induktionsanfang: Eigenschaft hält für ein kleines n. Als nächstes folgt der Induktionsschritt: Die Annahme ist, dass wir es bereits für ein kleineres n gezeigt haben und wenn die Eigenschaft für kleinere n hält, dann hält sie auch für das nächstgrößere n!

Nun wollen wir die obere Grenze für den Aufwand bestimmen. Unsere Vermutung ist, dass  . Nun müssen wir zeigen, dass
. Nun müssen wir zeigen, dass  ( siehe Definition der O-Notation). Die vereinfachte Annahme lautet
( siehe Definition der O-Notation). Die vereinfachte Annahme lautet  . Hierbei werden keine Spezialfälle behandelt und im Induktionsschritt wird von
. Hierbei werden keine Spezialfälle behandelt und im Induktionsschritt wird von  nach n gegangen.
nach n gegangen.
Induktionsvermutung:

Induktionsschritt: Wir beweisen von 
zu zeigende obere Grenze:

Rekursionsgleichung einsetzen:

Induktionsvermutung einsetzen:






Somit ist der Induktionsschritt erfolgreich, wenn  .
.
Induktionsanfang
Wir zeigen die Induktionsvermutung für einen Anfangswert, am einfachsten ist es, dies für den Rekursionsabbruch zu zeigen.
Zu zeigende obere Grenze:

Rekursionsgleichung einsetzen:

Der Induktionsanfang ist erfolgreich, wenn  ist. Doch wann können wir zeigen, dass
ist. Doch wann können wir zeigen, dass  ist? Für den Wert, den wir im Induktionsanfang gezeigt haben, also für
ist? Für den Wert, den wir im Induktionsanfang gezeigt haben, also für  und wenn
und wenn  .
.

Nun wollen wir die obere Grenze für den Aufwand bestimmen. Unsere Vermutung ist, dass  . Nun müssen wir zeigen, dass
. Nun müssen wir zeigen, dass  . Die vereinfachte Annahme lautet .
. Die vereinfachte Annahme lautet .
Induktionsvermutung:

Induktionsschritt: Wir beweisen von





Das Problem ist nun, dass wir den Induktionsschritt für positive n zeigen wollen und nicht für negative, daher müssen wir neu ansetzen.
Induktionsvermutung:
Dabei gibt es folgenden Trick: Modifiziere die Induktionsvermutung, in dem ein kleineres Polynom addiert wird.

Induktionsschritt: Wir beweisen von







Induktionsanfang für n=1



Wann können wir nun zeigen, dass ?
Für  . Somit haben wir gezeigt, dass
. Somit haben wir gezeigt, dass 
Da die Vorlesungsinhalte auf dem Buch Algorithmen und Datenstrukturen: Eine Einführung mit Java von Gunter Saake und Kai-Uwe Sattler aufbauen, empfiehlt sich dieses Buch um das hier vorgestellte Wissen zu vertiefen. Die auf dieser Seite behandelten Inhalte sind in Kapitel 7.2.5 zu finden.
Auf dieser Seite wird das Master Theorem behandelt.
Die Mastermethode ist ein „Kochrezept“ zur Lösung von
Rekursionsgleichungen der Form:
 mit den Konstanten
mit den Konstanten  , f(n) ist eine asymptotische, positive Funktion, d.h.
, f(n) ist eine asymptotische, positive Funktion, d.h. 
- a steht dabei für die Anzahl der Unterprobleme.
- n/b ist die Größe eines Unterproblems
- T(n/b) ist der Aufwand zum Lösen eines Unterproblems (der Größe n/b)
- f(n) ist der Aufwand für das Zerlegen und Kombinieren in bzw. von Unterproblemen
Bei der Mastermethode handelt es sich um ein schnelles Lösungsverfahren zur Bestimmung der
Laufzeitklasse einer gegebenen rekursiv definierten
Funktion. Dabei gibt es 3 gängige Fälle:
- Fall 1: Obere Abschätzung
- Fall 2: Exakte Abschätzung
- Fall 3: Untere Abschätzung
Lässt sich keiner dieser 3 Fälle anwenden, so muss die Komplexität anderweitig bestimmt werden und
wir müssen Voraussetzungen für die Anwendung des
Mastertheorems überprüfen.
Dafür vergleicht man mit  . Wir verstehen n/b als
. Wir verstehen n/b als  . Im Folgenden verwenden wir die verkürzte Notation
. Im Folgenden verwenden wir die verkürzte Notation  .
.
Wenn  . Daraus folgt, dass f(n) polynomiell langsamer wächst als um einen Faktor
. Daraus folgt, dass f(n) polynomiell langsamer wächst als um einen Faktor  . Damit haben wir die Lösung
. Damit haben wir die Lösung  .
.
Wenn  . Daraus folgt, dass f(n) und
. Daraus folgt, dass f(n) und  vergleichbar schnell wachsen. Damit haben wir die Lösung
vergleichbar schnell wachsen. Damit haben wir die Lösung  .
.
Wenn  und die Regularitätsbedingung
und die Regularitätsbedingung  für eine Konstante
für eine Konstante  und genügend große n erfüllt. Daraus folgt, dass f(n) polynomiell schneller wächst als um einen Faktor und f(n) erfüllt die sogenannte Regularitätsbedingung. Damit haben wir die Lösung
und genügend große n erfüllt. Daraus folgt, dass f(n) polynomiell schneller wächst als um einen Faktor und f(n) erfüllt die sogenannte Regularitätsbedingung. Damit haben wir die Lösung  .
.
In jedem Fall vergleichen wir f(n) mit  . Intuitiv kann man sagen, dass die Lösung durch die größere Funktion bestimmt wird.
Im zweiten Fall wachsen sie ungefähr gleich schnell. Im ersten und dritten Fall muss f(n) nicht nur kleiner oder größer als sein, sondern auch polynomiell kleiner oder größer um einen Faktor .
Der dritte Fall kann nur angewandt werden, wenn die
Regularitätsbedingung erfüllt ist.
. Intuitiv kann man sagen, dass die Lösung durch die größere Funktion bestimmt wird.
Im zweiten Fall wachsen sie ungefähr gleich schnell. Im ersten und dritten Fall muss f(n) nicht nur kleiner oder größer als sein, sondern auch polynomiell kleiner oder größer um einen Faktor .
Der dritte Fall kann nur angewandt werden, wenn die
Regularitätsbedingung erfüllt ist.
Regularitätsbedingung[Bearbeiten]
Doch wozu wird die Regularitätsbedingung benötigt? Zur Erinnerung, im dritten Fall dominiert f(n) das Wachstum von T(n). Wir müssen an dieser Stelle sicherstellen, dass auch bei rekursivem Anwenden, also wenn die Argumente kleiner werden, T(n) von f(n) dominiert wird. Veranschaulicht heißt das:


für  Das Wachstum muss durch f(n) dominiert werden und darf f(n) nicht dominieren.
Das Wachstum muss durch f(n) dominiert werden und darf f(n) nicht dominieren.
Die Regularitätsbedingung gilt wenn sie für f(n) und g(n) gilt auch für  und auch für
und auch für 
Nachweis für
Voraussetzung ist, dass die Regularitätsbedingung für f(n) und g(n) gilt, d.h.:


Für  gilt:
gilt:

man wählt 
und 

Nachweis für
Voraussetzung ist, dass die Regularitätsbedingung für f(n) und g(n) gilt, d.h.:
Für  gilt:
gilt:

man wählt 
und

Ist T(n) eine rekursiv definierte Funktion der Form

Dann gilt:
- 1. Fall: Wenn

- 2. Fall: Wenn

- 3. Fall: Wenn
 und
und  und genügend große n dann
und genügend große n dann 
Wir haben folgenden Rekursionsbaum:
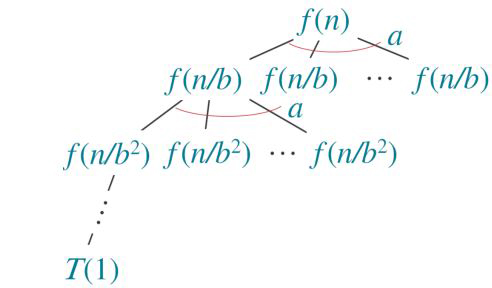
Auf der ersten Ebene ist der Aufwand f(n), auf der zweiten Ebene  und auf der dritten Ebene
und auf der dritten Ebene  . Die Höhe des Baumes beträgt
. Die Höhe des Baumes beträgt  . Die Anzahl der Blätter berechnet sich durch
. Die Anzahl der Blätter berechnet sich durch  und beträgt somit
und beträgt somit  .
.
Fall 1:
Das Gewicht wächst geometrisch von der Wurzel zu den Blättern. Die Blätter erhalten einen konstanten Anteil des Gesamtgewichts.

Fall 2:
k ist 0 und das Gewicht ist ungefähr das Gleiche
auf jedem der  Ebenen.
Ebenen.

Fall 3:
Das Gewicht reduziert sich geometrisch von der Wurzel zu den Blättern. Die Wurzel erhält einen konstanten Anteil am Gesamtgewicht.




Fall 1:




Fall 2:




Fall 3:

und  (Regularitätsbedingung)
(Regularitätsbedingung)
für 



Welcher Fall liegt nun vor? Das Mastertheorem kann an dieser Stelle nicht benutzt werden, da
- 1. Fall

- 2. Fall

- 3. Fall



- Vergleiche Logarithmus vs. Polynom




Auf dieser Seite wird das Thema Rekursionsbäume behandelt. Das allgemeine Problem ist, dass man zum Abschätzen von der Aufwandsklasse einer Rekursionsgleichung gute Vermutungen braucht. Doch wie kommt man darauf? Ein Ansatz ist die Veranschaulichung durch einen Rekursionsbaum. Die Aufwandsklasse wird dann durch die Rekursionsbaummethode bestimmt. Das ist sehr nützlich, um eine Lösung zu raten, die danach durch eine andere Methode (z.B. Induktion) gezeigt wird. Rekursionsbäume sind besonders anschaulich bei Divide-and-Conquer-Algorithmen.
Spezialfall Divide and Conquer[Bearbeiten]
Bei MergeSort sehen die Divide and Conquer Schritte wie folgt aus:
- Divide: Zerteile eine Folge mit n Elementen in zwei Folgen mit je n/2 Elementen.
- Conquer: Wenn die resultierende Folge 1 oder 0 Elemente enthält,dann ist sie sortiert. Ansonsten wende MergeSort rekursiv an.
- Combine: Mische die zwei sortierten Teilfolgen.

public List mergeSort(List f) {
if (f.size() <= 1) {
return f;
} else {
int m = f.size() / 2;
List left = mergeSort(f.subList(0,m));
List right = mergeSort(f.subList(m,f.size());
return merge(left, right);
}
}


Herleitung des Aufwandes[Bearbeiten]
Die Grundidee ist das wiederholte Einsetzen der
Rekursionsgleichung in sich selbst als Baum dargestellt. Das Ziel ist ein Muster zu erkennen.
Bei einem Rekursionsbaum beschreibt ein Knoten die Kosten eines Teilproblems. Die Blätter sind die Kosten der Basis fällt T(0) und T(1). Der Aufwand bestimmt sich aus der Summe über alle Ebenen.
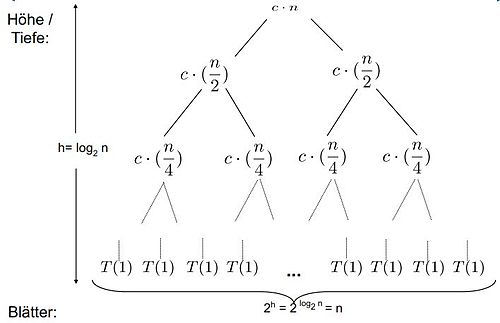
1. Ebene 
2. Ebene 
3. Ebene 
....
n. Ebene 
Der Aufwand berechnet sich nun wie folgt:





Allgemein bestimmt sich der Aufwand T(n) durch die Summe des Aufwands je Ebene und des Aufwands der Blattebene.
Bezogen auf den gegebenen Rekursionsbaum wäre das 
Da die Vorlesungsinhalte auf dem Buch Algorithmen und Datenstrukturen: Eine Einführung mit Java von Gunter Saake und Kai-Uwe Sattler aufbauen, empfiehlt sich dieses Buch um das hier vorgestellte Wissen zu vertiefen. Die auf dieser Seite behandelten Inhalte sind in Kapitel 8.3 zu finden.



