
Kurs:OpenKnowledge24/Lenskatala
Aufgaben zu Sitzung 2, 15.03.2024
[Bearbeiten]Gartenlaube, Seitenkorrektur
[Bearbeiten]… eine der Seiten im Jahrgang s:Die Gartenlaube (1898), insb. gelbe Seiten in s:Index:Die Gartenlaube (1898) …
Zuerst gewählte Seite: Ein Tag an Bord eines Eisbrechers; Heft 1/1898, S. 29-32

Etwas irritierend: Im Bearbeitungsstand wird nicht genau angegeben, welche Seiten des Artikels bereits Korrektur gelesen wurden. Index zeigt, dass bereits alle Seiten des Artikels grün sind.
Endgültige Wahl: Erkältung; Heft 1/1898, S. 26-28 (27 noch zu korrigieren) Anmerkungen zur Korrektur: Lediglich ein "Ü" musste durch "Ue" ersetzt werden. Markierungen im Text/Scan setzen zu können, wäre hilfreich. Kurze Verwirrung, wo das "fertig"-Label eingetragen wird, aber Seite ist jetzt grün.
… überprüfe und korrigiere bei Bedarf Metadaten der einzelnen Artikelseiten in den jeweiligen Wikidata-Items: Schlagworte/main subject, Bilder/image, Bildunterschriften/media legend.
Wikidata-Seite m.E. vollständig und korrekt.
Nearby
[Bearbeiten]Mein Nearby/Heimatdorf: Bartensleben (Groß Bartensleben hab ich auch noch dazu genommen. Fun Fact: Klein Bartensleben ist größer als Groß Bartensleben.)
Hinzugefügt:
- Saxony-Anhalt cultural heritage object ID
- englisches Label und Beschreibung
Hinzugefügt:
- Saxony-Anhalt cultural heritage object ID
Aufgaben zu Sitzung 3, 22.03.2024
[Bearbeiten]Wie gut ist das Straßennetz von Hannover in Wikidata und Commons erschlossen?
[Bearbeiten]Testobjekt I: Stöckener Straße
Status vor Bearbeitung:
- Warum werden die "Connects with" nicht automatisch angezeigt, so wie z.B. bei Achtbeeteweg in Dresden? (Anzahl?)
- Wie lange bis zur Aktualisierung des Infokastens?
Bearbeitungen auf Wikidata-Seite:
- connects with Fuhsestraße hinzugefügt
- connects with Herrenhäuser Straße hinzugefügt
- ... und weitere fehlende connects with hinzugefügt und bei diesen dann wiederum Stöckener Straße hinzugefügt
Stöckener Straße bei Nearby
Hinzugefügte Straßen tauchen bei Nearby auf, aber auch vorher?
Testobjekt II: Herrenhäuser Straße Koordinaten von Bäcker Ecke Herrenhäuser Straße/Haltenhoffstraße --> Nearby --> Haltenhoffstraße ist kein connects with von Herrenhäuser Straße --> taucht (noch) nicht bei nearby auf
WikiShootMe!
[Bearbeiten]Bild zu Bahnhof Immensen-Arpke hinzugefügt
Aufgaben zu Sitzung 4, 05.04.2024
[Bearbeiten]Nach den ersten drei Kursen zum Einstieg ins Wikiversum: Welche Fragen sind offen? Was möchtest du noch vertiefen?
[Bearbeiten]Die Wikimedia-Projekte leben von ihrer Verknüpfung untereinander. Ich glaube, mir hätte es geholfen, die verschiedenen Seiten zunächst getrennt voneinander intensiver zu betrachten. Ich freue mich jedoch darauf, mich stärker in die Wikimedia Commons und Wikidata einzuarbeiten. Zum einen würde ich mich dort gerne den "underdogs" widmen, also der Datenpflege von kleinen Ortschaften wie meinem Heimat- oder Wohnort. Generell würde ich dadurch gern mein Interesse für Fotografie in etwas Sinnvolles umsetzen.
Was war/ist/funktioniert für Dich schon gut bzw. noch nicht?
[Bearbeiten]Ich bin schon eine Weile im Internet unterwegs und auch mit Internetseiten vertraut, deren Design man gnädigerweise als "old-school" beschreiben kann. Die Oberfläche der Wikimedia-Seiten ist schlicht und zweckgebunden, was nicht falsch ist. Meine persönliche Nutzererfahrung hätte jedoch von etwas mehr Farbe profitieren können. Ja, man kann die einzelnen Wikimedia-Projekte sind im Browser an den unterschiedlichen Favicons zu erkennen, aber zur schnelleren Orientierung auf der Seite hätte ich mir farblich verschieden gestaltete Seitenpanels gewünscht. Ich habe zudem viele Jahre mit Wordpress gearbeitet, dort funktioniert vieles mit drag-and-drop, besonders der Upload von Bildern ist unkompliziert. Dass es bei Wikimedia Commons dagegen nicht so intuitiv abläuft, ist für mich zum einen frustrierend und andererseits auch zeitaufwendiger. Abhilfe schaffe ich mir, indem ich ein ähnliches Objekt in einem zweiten Tab geöffnet habe und dann entsprechend die Einstellungen und Informationen übernehme, aber ein flüssiger Arbeitsablauf ist das noch nicht wirklich.
Notizen Data Harvesting, Sitzung 5, 05.04.2024
[Bearbeiten]- IIIF
- Zu Aufgabe Explore the Entity API: z.B. Leonardo da Vinci in Europeana über Wikidata-ID finden
Aufgaben zu Sitzung 6, 12.04.2024
[Bearbeiten]Optionale Aufgaben
[Bearbeiten]Noch in Arbeit: Jupyter Notebook zu OAI-PMH angelegt
Pflichtaufgaben
[Bearbeiten]Auswahl Datensatz
[Bearbeiten]Von Pflanzenbelege aus dem Botanischen Garten Berlin gewechselt zu Schriftprobensammlung des BGBM - lässt sich eventuell mit OCR-Hausarbeit für BIM-214-02 kombinieren.
Download Open Refine
[Bearbeiten]- Erledigt.
- Lassen sich damit auch JSON-Dateien abspeichern? Wo werden die Daten zwischengespeichert?
Download Daten
[Bearbeiten]- uagh...
- API ist irreführend: /list{id} "gets all information about the autograph with the specified id" ist aber tatsächlich die AutorenID
- wenn explizit nach "ID" oder "DokumentID" gesucht wird --> 404
- ganz wichtig: Python-Skript für sowas schreiben...
Nachtrag
[Bearbeiten]Mittels ChatGPT Skript für automatisierten Download schreiben lassen.
import requests import json import os
- Erstellen Sie einen Ordner mit dem Namen 'downloads', wenn er noch nicht existiert
if not os.path.exists('downloads'):
os.makedirs('downloads')
- Iterieren Sie über die IDs von 1 bis 1362
for id in range(100, 1363):
# Setzen Sie die URL zusammen url = f"https://api.bgbm.org/autographs/v1/list/{id}"
# Versuchen Sie die Anfrage
try:
response = requests.get(url)
except requests.exceptions.RequestException as e:
print(f'An exception occurred for id {id}:', e)
continue
# Überprüfen Sie den Statuscode der Antwort
if response.status_code == 200:
# Wenn die Anforderung erfolgreich ist, speichern Sie die Antwort als JSON
with open(f'downloads/{id}_BGBM.json', 'w') as outfile:
json.dump(response.json(), outfile)
elif response.status_code == 404:
print(f'No page found for id {id}, skipping...')
continue
else:
print(f'Received unexpected status code {response.status_code} for id {id}, skipping...')
Aufgaben zu Sitzung 7, 19.04.2024
[Bearbeiten]Präsentation Datensatz
[Bearbeiten]Direkt auf der Kursseite eingebunden.
Group task 1
[Bearbeiten]Pick 1 object from your dataset and try to represent the metadata of the object in semantic triples.
-
 Originalversion
Originalversion -
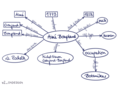 Korrektur
Korrektur


Aufgaben zu Sitzung 8, 26.04.2024
[Bearbeiten]Ausfall der VA
Homework
[Bearbeiten]Update Dataset
[Bearbeiten]Direkt auf Kursseite eingebunden.
Diagram
[Bearbeiten]Prepare a diagram of a data model representing your dataset in Wikidata.

Finale Abgabe zum 17.05.2024
[Bearbeiten]Ein paar Anmerkungen zum Upload
[Bearbeiten]- auf die ca. 60 noch nicht in Wikidata vorhandenen Personen beschränkt
- given name + Vornamen wurden nicht übernommen --> Was muss da beim Reconciling beachtet werden? Warum muss da überhaupt reconcilet werden?
- große Probleme Botanikerkürzel einzufügen
- es wurden weniger neue Items angelegt als Zeilen pro Upload ausgewählt waren
SPARQL-Abfragen
[Bearbeiten]Erste Abfrage
[Bearbeiten]
Zweite Abfrage
[Bearbeiten]
Dritte Abfrage
[Bearbeiten]- Sollte eigentlich ein Balkendiagramm mit Anzahl der weiblichen und männlichen Botaniker:innen sein, aber ...
Aufgaben zum 30.05.2024
[Bearbeiten]Raum in Schlossanlage Weikersheim
[Bearbeiten]- Tafelstube angelegt als part of Schlossanlage Weikersheim
- Text und Bild zu Tafelstube angelegt
Aufgaben zum 07.06.2024
[Bearbeiten]Weiterer Dateiupload zu Wikibase
[Bearbeiten]| Ebene | Element | Art | Kürzel |
|---|---|---|---|
| 1 | Tafelstube | part of | Q231 |
| 1 | Tafelstube Schlossanlage Weikersheim text | text | Q232 |
| 1 | Einstige Tafelstube & Raum 69a – nach Südosten | image | Q234 |
| 2 | Belagerungsszenen des Langen Türkenkrieges | part of | Q237 |
| 2 | Belagerungsszenen des Langen Türkenkrieges text | text | Q278 |
| 3 | Belagerung I: „Vestung Tottis, wie die von den Christen bei der Nacht erobert wo | part of | Q238 |
| 3 | Belagerung II: „Vestung Gran wie die von Christen belegert gewesen. 1594“ | part of | Q239 |
| 3 | Belagerung III: „Vestung Raab, wie die vom Türcken belegert gewesen. A[nn]o 1594 | part of | Q240 |
| 3 | Belagerung IV: „Vestung Comorna wie die vom Türckn belegert gewe[sen] 1594“ | part of | Q241 |
| 3 | Belagerung V: „Vestung Gran wie die von den Christen wider erobert worden. A[nn] | part of | Q242 |
| 3 | Belagerung VI: “Vestung Vizzegrad wie die von Christen belegert gewesen Anno 159 | part of | Q243 |
| 3 | Belagerung VII: „Statt Waitzen wie die von vom Türcken belegert gewesen 1597“ | part of | Q244 |
| 3 | Belagerung VIII: „Vestung Raab, die Christen beÿ der Nacht wider erobert. A[nn]o | part of | Q245 |
| 3 | Belagerung IX: „Hauptstatt Offen. wie die von Christen belegert gewesen. 1598.“ | part of | Q246 |
| 3 | Belagerung X: „Hauptstatt Offen, wie die von Christen belegert gewesen. Anno 160 | part of | Q247 |
| 3 | Belagerung XI: „Hauptstatt Offen, wie die von Christn belegert gewesen, ein Schä | part of | Q248 |
| 3 | Belagerung XII: „Vestung Gran wie die vom Türcken belegert gewesen A[nn]o 1604“ | part of | Q249 |
| 3 | Belagerungsszene I Schlossanlage Weikersheim text | text | Q252 |
| 3 | Belagerungsszene II Schlossanlage Weikersheim text | text | Q253 |
| 3 | Belagerungsszene III Schlossanlage Weikersheim text | text | Q254 |
| 3 | Belagerungsszene IV Schlossanlage Weikersheim text | text | Q255 |
| 3 | Belagerungsszene V Schlossanlage Weikersheim text | text | Q256 |
| 3 | Belagerungsszene VI Schlossanlage Weikersheim text | text | Q257 |
| 3 | Belagerungsszene VII Schlossanlage Weikersheim text | text | Q258 |
| 3 | Belagerungsszene VIII Schlossanlage Weikersheim text | text | Q259 |
| 3 | Belagerungsszene IX Schlossanlage Weikersheim text | text | Q260 |
| 3 | Belagerungsszene X Schlossanlage Weikersheim text | text | Q261 |
| 3 | Belagerungsszene XI Schlossanlage Weikersheim text | text | Q262 |
| 3 | Belagerungsszene XII Schlossanlage Weikersheim text | text | Q263 |
| 2 | Programm und Synthese der einstigen Tafelstube Schlossanlage Weikersheim text | text | Q265 |
| 3 | I: Eroberung der Festung Tottis – Gesamtansicht | image | Q265 |
| 3 | II: Belagerung der Festung Gran – Gesamtansicht (1594) | image | Q266 |
| 3 | III: Belagerung der Festung Raab – Gesamtansicht | image | Q267 |
| 3 | IV: Belagerung der Festung Comorna – Gesamtansicht | image | Q268 |
| 3 | V: Eroberung der Festung Gran – Gesamtansicht | image | Q269 |
| 3 | VI: Belagerung der Festung von Visegrád – Gesamtansicht | image | Q270 |
| 3 | VII: Belagerung der Stadt Waitzen – Gesamtansicht | image | Q271 |
| 3 | VIII: Wiedereroberung der Festung Raab – Gesamtansicht | image | Q272 |
| 3 | IX: Belagerung der Stadt Ofen im Jahr 1598 – Gesamtansicht | image | Q273 |
| 3 | X: Belagerung der Stadt Ofen im Jahr 1603 – Gesamtansicht | image | Q274 |
| 3 | XI: Belagerung der Festung Gran – Gesamtansicht (Anno 1604) | image | Q275 |
| 3 | XII: Scharmützel bei der Belagerung der Stadt Ofen im Jahr 1603 – Gesamtansicht | image | Q276 |
Finale Abgabe
[Bearbeiten]- Fußnoten ließen sich nicht umsetzen
- ursprüngliche Formatierung [1] wurde im Markdown-Text durch [^1] sowie am Dokumentende durch [^1]: ersetzt, wurden aber trotzdem nicht gerendert
- in der Ausgabe steht ein Backslash vor der eckigen Klammer --> Könnte das der Grund sein?