
Torerzielung Fußball
Modellierungsproblem
[Bearbeiten]In einem Fußballspiel können von verschiedensten Positionen zu unterschiedlichsten Zeiten Tore erzielt werden. In diesem Projekt sollen die Tore des FC Bayern München in der Bundesliga Saison 2017/18 genauer untersucht werden. Dabei soll die Position, von der das Tor erzielt wurde, sowie der Zeitpunkt des Tores analysiert werden. Die beiden Komponenten sollen dabei zunächst getrennt untersucht werden und erst am Ende ggf. zusammengeführt werden. Hieraus sollen mögliche taktische Erkenntnisse herausgefiltert werden, die die gegnerischen Teams für die eigene Handlung nutzen können.

Zielsetzung
[Bearbeiten]- Analyse der Häufigkeiten, von wo aus die Tore gefallen sind (Wahrscheinlichkeit für verschiedene Positionen bestimmen)
- Analyse der Häufigkeiten, wann die Tore gefallen sind (Wahrscheinlichkeit für die verschiedenen Zeitpunkte bestimmen)
- Zusammensetzung der beiden Komponenten, um herauszufinden zu welchem Zeitpunkt der FC Bayern München über die verschiedenen Positionen versucht ein Tor zu erzielen
- Gewinnung von Daten für die gegnerischen Teams, um eine geeignete Taktik für die Torverhinderung zu kreieren
Niveaustufen
[Bearbeiten]Im Folgenden werden verschiedene Anwendungsmöglichkeiten für unterschiedliche Niveaustufen aufgezeigt.
- Sek I-Niveau
- Absolute und relative Häufigkeit
- Datenerhebungen planen, durchführen und auswerten
- graphische Darstellungen erstellen und interpretieren, funktionaler Zusammenhang
- Tabellenkalkulation und Graphenerstellung mit Excel
- Sek II-Niveau
- Erwartungswert, Varianz und Standardabweichung
- Zuordnung der Positionen zu den Zeitintervallen
- Universitätsniveau
- Lineare Regression und Bestimmtheitmaß
- Gewichtsfunktion und gleitender Mittelwert
- Verteilungsfunktion und Dichtefunktion
Testdaten
[Bearbeiten]
Um an die kompletten Daten für die Saison 2017/18 zu kommen, mussten wir uns über den YouTube Kanal des Streaming Anbieters DAZN alle 34 Bundesligaspiele des FC Bayern München anschauen. Hierbei notierten wir uns zu jedem gefallenen Tor die genaue Spielminute. Um die Position des gefallenen Tores besser analysieren zu können, haben wir uns das Spielfeld in ein Raster eingeteilt und notierten uns so von wo das Tor erzielt wurde.
Den 92 geschossenen Toren wurden dann in einer Tabelle jeweils der Zeitpunkt und die Position zugeordnet.
Ausschnitt der Testdaten
[Bearbeiten]| Spieltag | Gegner | Minute | Position | Spieler | Elfmeter |
|---|---|---|---|---|---|
| 1 (H) | Bayer Leverkusen (3:1) | 9 | G2 | Süle | |
| 1 (H) | Bayer Leverkusen (3:1) | 18 | G1 | Tolisso | |
| 1 (H) | Bayer Leverkusen (3:1) | 53 | F3 | Lewandowski | x |
| 2 (A) | Werder Bremen (0:2) | 72 | G2 | Lewandowski | |
| 2 (A) | Werder Bremen (0:2) | 75 | E4 | Lewandowski |
Die komplette Tabelle finden Sie hier.
Zyklus 1
[Bearbeiten]Zyklus 1.1
[Bearbeiten]Reale Situation: Torerfolg beim Fußball
[Bearbeiten]Der FC Bayern München erzielte in der Bundesligasaison 17/18 92 Tore. Die Tore wurden zu verschiedenen Zeitpunkten, von unterschiedlichen Positionen, von verschiedenen Spielern erzielt.
Reales Modell: Einteilung des Spielfeldes in ein Raster
[Bearbeiten]Die Spielfeldmaße wurden für neugebaute Stadien von der DFL wie folgt festgelegt:
Breite: 68m
Länge: 105m

Um besser rechnen zu können setzen wir die Länge auf 104m.
Tore werden, bis auf vernachlässigbar wenige Fälle, in der gegnerischen Spielfeldhälfte erzielt.
Breite: 68m
Länge: 104m / 2 = 52m
Für das Raster legen wir 11 Bereiche in der Breite und 11 Bereiche in der Länge fest.
Mathematisches Modell: Geschossene Tore in das Raster eintragen
[Bearbeiten]Wir werten die 92 Torerfolge aus und tragen die Positionen der erzielten Tore in das erstellte Raster ein.


Mathematische Resultate: Auswertung des Rasters
[Bearbeiten]Zur Auswertung des erstellten Rasters, generieren wir eine Heatmap. Zusätzlich werten wir die Daten der Tabelle aus und stellen sie graphisch dar.
Reale Resultate: Interpretation der Heatmap und der Graphen
[Bearbeiten]Nun interpretieren wir die Heatmap zurück auf die reale Situation. Hieraus erkennen wir, dass mit 38 Treffern mit Abstand die meisten Tore in der Zone D2-H2 erzielt wurden. Das entspricht in der Realsituation auf dem Spielfeld dem Bereich im Strafraum auf Höhe der 5m-Linie. Aus dem Bereich auf Höhe des 11m-Punktes vielen mit 24 Treffern weniger Tore, dennoch beachtlich viele. Im Bereich E1-G1 erzielte der FC Bayern München gerade einmal knapp 16% seiner Tore. Die gewonnenen Erkenntnisse ergeben durchaus Sinn. Der Bereich D2-H2 liegt unmittelbar vor dem Tor. Auf diesen hat der Torhüter der Gegnermannschaft jedoch nur bedingt Zugriff im Vergleich zu Bereich E1-G1. Außerdem ist dieser Raum sehr oft Ziel bei den Standardsituationen wie Eckball oder Freistoß. Dazu kommt, dass Pässe von der Torgrundlinie in der Regel in diesem Bereich ihren Abnehmer finden.
Unschwer zu erkennen ist ebenfalls, dass in der vertikalen Ausrichtung im Bereich F1-F5 die meisten Tore erzielt wurden. Von hieraus stehen dem Torschützen alle Möglichkeiten des Torerfolgs offen. Aus den Bereichen E1-E5 und G1-G5 kann der gegnerische Torhüter durch geschicktes Torhüterspiel sehr viel besser einen Torerfolg verhindern.
Betrachten wir nun die Heatmap als Ganzes. So erkennen wir, dass augenscheinlich fast alle Treffer im Strafraum oder seiner unmittelbaren Umgebung fallen. Demnach könnte eine Betrachtung des Bereichs C1-4 bis I1-4 für aussagekräftige Erkenntnisse genügen.
Betrachten wir die Verteilung der Tore über die Zeit, erkennen wir zu Beginn einer Fußballpartie das berühmte "Abtasten". Hier fallen sehr wenige Tore genauso wie zu Anfang der zweiten Halbzeit. Die Team reagiert abwartend auf den Gegner und die Sinne sind noch nicht geschärft. Das Gegenteil erkennen wir zum jeweiligen Halbzeitende. Die Spieler sind voller Adrenalin, kurz vor Schluss will jeder noch einmal sein volles körperliches Leistungspotenzial ausschöpfen und gleichzeitig schwindet die kognitive Leistungsfähigkeit und Belastbarkeit der Abwehrspieler des Gegners. Die erhöhte Toranzahl ist das Ergebnis dieses Prozesses.
Zyklus 1.2 - Erwartungswert, Varianz und Standardabweichung
[Bearbeiten]Reale Situation/Reales Modell: Unterschiedliche Torzeitpunkte
[Bearbeiten]Im ersten Zyklus wurden die unterschiedlichen Torzeitpunkte erfasst. Während zu Beginn des Spiels nur wenig Tore geschossen wurden, steigt mit fortschreitender Spieldauer auch die Anzahl der erzielten Tore an. Die zweite Spielhälfte gestaltet sich analog. Auffällig ist nur ein rasanter Anstieg der Tore ab der 85. Spielminute.
Mathematisches Modell/Mathematische Resultate: Bestimmung relativer Häufigkeiten/Berechnung Erwartungswert, Varianz, Standardabweichung
[Bearbeiten]Im nächsten Schritt werden die relativen Häufigkeiten der einzelnen Spielminuten berechnet.
Im Folgenden werden, mit Hilfe des Tabellenkalkulationsprogramms Excel, der Erwartungswert, die Varianz und die Standardabweichung berechnet.



Reale Resultate: Interpretation
[Bearbeiten]Der Erwartungswert des Torerzielungszeitpunktes liegt kurz nach der Halbzeit. Dies lässt sich durch die vielen geschossenen Tore am Anfang und Ende des Spiels begründen. Der Wert der Standardabweichung von lässt sich so interpretieren, dass in dieser Abweichungsgröße vom Erwartungswert die meisten Tore erzielt wurden.

Zyklus 1.3 - Unterteilung der Spiels in Intervalle
[Bearbeiten]Im zweiten Zyklus wurden nicht nur die mathematischen Werte wie die Varianz oder der Erwartungswert berechnet, sondern es wurde auch erstmals der Zeitpunkt und die Position des Tores kombiniert. In einem Zeitintervall von fünf Minuten wurden jeweils die Positionen der gefallenen Tore ermittelt und in das Raster aus dem ersten Zyklus eingetragen. Aus den 18 erhaltenen Bildern wurde schließlich eine kleine Animation erstellt, um die Unterschiede zwischen den einzelnen Zeitintervallen darzulegen. Anbei ein kleiner Ausschnitt mit sechs Zeitintervallen.
-
 Position der erzielten Tore zwischen der 01. und der 05. Minute in der Saison 2017/18 des FC Bayern München
Position der erzielten Tore zwischen der 01. und der 05. Minute in der Saison 2017/18 des FC Bayern München -
 Position der erzielten Tore zwischen der 16. und der 20. Minute in der Saison 2017/18 des FC Bayern München
Position der erzielten Tore zwischen der 16. und der 20. Minute in der Saison 2017/18 des FC Bayern München -
 Position der erzielten Tore zwischen der 26. und der 30. Minute in der Saison 2017/18 des FC Bayern München
Position der erzielten Tore zwischen der 26. und der 30. Minute in der Saison 2017/18 des FC Bayern München -
 Position der erzielten Tore zwischen der 61. und der 65. Minute in der Saison 2017/18 des FC Bayern München
Position der erzielten Tore zwischen der 61. und der 65. Minute in der Saison 2017/18 des FC Bayern München -
 Position der erzielten Tore zwischen der 81. und der 85. Minute in der Saison 2017/18 des FC Bayern München
Position der erzielten Tore zwischen der 81. und der 85. Minute in der Saison 2017/18 des FC Bayern München -
 Position der erzielten Tore zwischen der 86. und der 90. Minute in der Saison 2017/18 des FC Bayern München
Position der erzielten Tore zwischen der 86. und der 90. Minute in der Saison 2017/18 des FC Bayern München
.png)
.png)
.png)
.png)
.png)
.png)
Zyklus 1.4 - Lineare Regression
[Bearbeiten]Betrachtung des linearen Zusammenhangs zwischen dem Zeitpunkt im Spiel und der Anzahl der Tore (Lineare Regression): Nun untersuchen wir, ob es einen weiteren Zusammenhang zwischen der Anzahl an Toren und der Spielzeit gibt.

Mit Hilfe des Tabellenkalkulationprogrammes Excel nutzen wir die Methode der linearen Regression, um einen linearen Zusammenhang zwischen der Zeit und der Anzahl an erzielten Toren zu untersuchen. Dabei erhalten wir die Funktionsgleichung der Regressionsgeraden . Auffällig ist hier die geringe Steigung der Regressionsgeraden, die keinen linearen Zusammenhang vermuten lässt.

Um einen linearen Zusammenhang tatsächlich ausschließen zu können, bestimmen wir das Bestimmtheitmaß . Folglich können wir also von keinem linearen Zusammenhang zwischen der Spielminute und der Anzahl an erzielten Toren ausgehen.

Zyklus 1.5 - Erweiterung der Testdaten
[Bearbeiten]
Zunächst bemühen wir uns um eine Erweiterung der Tabelle um weitere Werte. Hierzu wurden die Champions-League Spiele der Saison 2016/17 und 2017/18 untersucht und in der Tabelle aus Zyklus 1 eingetragen. Zusätzlich präzisieren wir die Positionen der gefallenen Tore. Dazu bestimmen wir für jedes Tor den exakten xi- und einen yi-Wert. Der Nullpunkt ist dabei die linke Eckfahne (siehe Bild rechts). Damit ist sicher gestellt, dass alle Werte eindeutig sind und es keine negativen Werte gibt. Somit gibt der xi Wert die Entfernung von der Torauslinie zur Torschussposition an und der yi Wert die Entfernung von der linken Seitenauslinie zur Torschussposition.
Mit der neuen Testdatentabelle erhoffen wir uns, dass die zuvor geäußerten Vermutungen noch signifikanter werden. Zusätzlich erhalten wir mehr Werte, mit denen wir im weiteren Verlauf der Zyklen rechnen können. Sie liegen als Excel-Datei bereits komplett vor und ist hier ausschnittsweise zu sehen.

Mit den neu gewonnenen Werten wurde nun eine finale Heatmap angelegt. Die Werte dieser Heatmap bilden nun die Grundlage für das Vorgehen in den weiteren Zyklen.

Zyklus 2
[Bearbeiten]Gewichtsfunktion
[Bearbeiten]Gibt es eine Funktionsvorschrift, die unser linear angenähertes und visualisiertes Problem noch genauer darstellen kann? Wie sieht diese Funktionsvorschrift aus?
Die folgende Funktion
- ;

![{\displaystyle s\in [0.1,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/51d7219f2cf27ae3add01419fca641db0cae646d)
beschreibt einen "Hügel" und lässt mit entsprechenden Modifikationen auf eine "Hügellandschaft" hoffen, wie wir sie benötigen und annähern wollen. Anbei sind einige Ausschnitte zu der Funktion und deren Veränderung dargestellt, die sich durch die Änderung des Parameters s ergibt. Deutlich zu erkennen ist, dass die Steigung um den Hügel steiler wird, wenn der Parameter kleiner gewählt wird. Wählt man den Parameter größer, so flacht die Steigung um den Hügel deutlich ab, und die Werte rund um den Mittelpunkt werden größer.
-
 Gewichtsfunktion mit Parameter s=0.11
Gewichtsfunktion mit Parameter s=0.11 -
 Gewichtsfunktion mit Parameter s=0.6
Gewichtsfunktion mit Parameter s=0.6 -
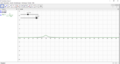 Gewichtsfunktion mit Parameter s=0.91
Gewichtsfunktion mit Parameter s=0.91



Im folgenden setzen wir den Parameter s auf 0.1 fest und rechnen damit weiter.
Gleitender Mittelwert
[Bearbeiten]Mithilfe der Gewichtsfunktion ist nun der nächste Schritt, den gleitenden Mittelwert der einzelnen Felder aus dem Raster zu bilden. Dazu wurde jede Zeile und jede Spalte separat betrachtet. Zu einem beliebigen Feld wurde dann die Anzahl der geschossenen Tore, die von diesem Feld aus erzielt wurden, mit der Gewichtsfunktion gewichtet. Dies wurde außerdem mit dem Vorgänger- sowie dem Nachfolgerfeld getan. Die drei gewichteten Funktionen wurden nun aufsummiert und bilden so die Mittelwertfunktion dieses Feldes.

Dabei gilt:
- ki → Anzahl der geschossenen Tore des Feldes
- xi → Entfernung zum Ursprung (Linke Ecke)
- s → Parameter zur Steuerung der Gewichtsfunktion
- t → Gesamtanzahl der gefallenen Tore in der Zeile bzw. Spalte
In der folgenden Abbildung wurde die Mittelwertfunktion in der zweiten Zeile von Feld E gebildet


Summenfunktion
[Bearbeiten]Aus den gebildeten Mittelwertfunktionen werden nun die Summenfunktionen für die einzelnen Zeilen und Spalten gebildet. Dazu werden jeweils in jeder Zeile und in jeder Spalte die dazugehörigen Mittelwertfunktionen aufsummiert, es entsteht die Summenfunktion der Zeile bzw. der Spalte.

Betrachten wir weiterhin als Beispiel die zweite Zeile des Rasters. Da nicht in jedem Feld der Zeile ein Tor geschossen wurde, beginnen wir mit dem dritten Feld (Zeile 2, Feld C) und summieren die Mittelwertfunktionen bis zum neunten Feld (Zeile 2, Feld I) auf.


Dabei bilden f3(x) - f9(x) die einzelnen Mittelwertfunktionen, der Felder der zweiten Zeile. Die Summenfunktion der zweiten Zeile kann dem Bild rechts entnommen werden.
Dichtefunktion
[Bearbeiten]Im vorletzten Schritt gilt es nun, aus der Summenfunktion eine Wahrscheinlichkeitsdichtefunktion herzuleiten. Dazu betrachten wir zunächst die Definition:
Gegeben sei eine reelle Funktion
- , für die gilt:

- ist nichtnegativ, das heißt, für alle .
- ist integrierbar.
- ist normiert in dem Sinne, dass



- .

Dann heißt eine Wahrscheinlichkeitsdichtefunktion.
Offensichtlich besitzt unsere Summenfunktion bereits die ersten beiden Eigenschaften (Nichtnegativität & Integrierbarkeit).

Bildet man jedoch das Integral der Summenfunktion, so kommt als Endwert a=2,96 raus. Um eine Dichtefunktion zu erhalten müssen wir also die Summenfunktion noch normieren, in unserem Falle durch 2,96 teilen.

Nun sind für unsere Funktion alle drei Eigenschaften gegeben und wir erhalten somit eine Dichtefunktion.
Verteilungsfunktion
[Bearbeiten]Jede Verteilungsfunktion hat folgende Eigenschaften:
![{\displaystyle F\colon \mathbb {R} \rightarrow [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b4c45b6faf38bb3fb300ab4678d3675afd172f56)
- ist monoton steigend.
- ist rechtsseitig stetig.
- und .



Darüber hinaus ist jede Funktion , die die Eigenschaften 1, 2 und 3 erfüllt, eine Verteilungsfunktion. Folglich ist eine Charakterisierung der Verteilungsfunktion mit Hilfe der drei Eigenschaften möglich.
Betrachten wir weiterhin unser Beispiel "Zeile 2". Bildet man zu unserer Dichtefunktion nun das Integral, so erhalten wir folgende Funktion. Offensichtlich gelten hier alle 3 oben genannten Eigenschaften. Wir erhalten also eine Verteilungsfunktion.

Mit Hilfe der Verteilungsfunktion können wir nun die Wahrscheinlichkeiten einfach berechnen: Ist eine Verteilungsfunktion gegeben, so kann man wie folgt die Wahrscheinlichkeiten bestimmen:
- sowie bzw.
- sowie .


![{\displaystyle P((-\infty ;a])=F(a)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3c87fb872c6a3251f82fd21f908111708d1489a8)

Daraus folgt dann auch
- und

![{\displaystyle P((a;b])=F(b)-F(a)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fcc1d1c84afe5749824309e68d2c1aa581dcf21d)
für .

Durch einsetzen verschiedener Werte () können nun die Wahrscheinlichkeiten innerhalb der Zeile berechnet werden. Da wir bisher aber alle Zeilen und Spalten separat betrachtet haben, können wir auch nur die Wahrscheinlichkeiten innerhalb einer Spalte oder innerhalb einer Zeile berechnen. Daher werden wir im nächsten Zyklus von zweidimensionalen Raum in den dreidimensionalen Raum wechseln.
![{\displaystyle x\in [0,68]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c5426d8f10fe5089efe92843859628a49882ba30)
Zyklus 3
[Bearbeiten]Zyklus 3.1 - 3D Darstellung in GeoGebra
[Bearbeiten].png)
Im dritten Zyklus soll nun auf den 3 dimensionalen Raum erweitert werden. Dabei wird die Gewichtsfunktion aus Zyklus 2 um eine weitere Variable erweitert, sodass folgende Gleichung entsteht:
- ;

{kind=link}
{kind=link}
Analog zu der Vorgehensweise in Zyklus 2 wird auch hier zunächst der gewichtete gleitende Mittelwert gebildet und dann die Summenfunktion, sowie die Dichtefunktion. Nun muss zur Bildung der Verteilungsfunktion eine komplexere Funktion mit zwei Veränderlichen integeriert werden. Da hierbei die Rechenkapazität von GeoGebra an ihre Grenzen kommt, werden wir im Folgenden auf die Software Octave zurückgreifen.
Zyklus 3.2 - Darstellung in Octave
[Bearbeiten]Mit Hilfe von Octave können wir die umständliche und zeitraubende Eingabe der Funktion mit zwei Variablen automatisieren und vereinfachen. Des Weiteren arbeitet Octave mit Hilfe numerischer Berechnungen ressourcenschonender, was eine schnellere Berechnung und bessere Darstellung erlaubt vor allem im 3D-Bereich. Mit dem dargestellten Editor-Code sind wir nun in der Lage die Torverteilung und den gewichteten Mittelwert als Dichtefunktion darzustellen. Zukünftig könnten mit minimalsten Änderungen auch Torverteilungen von anderen Mannschaften oder einzelnen Spielern dargestellt werden. Der Nutzer kann den Parameter s und die Glättung, durch Änderung der Schrittweite u, selbst angeben.
Der Vergleich der Visualisierung der Rohdaten mit der Visualisierung mittels Dichtefunktion in Octave zeigt eine deutliche Glättung und Annäherung an die reale Situation.
Über die function trapz() mit zwei Variablen können für entsprechende Intervalle die Wahrscheinlichkeiten errechnet werden. Dies könnte wie folgt aussehen:
%Trapz function, Parameter 2, wsumme matrix, xfeld und yfeld als mesh
I=trapz(yfeld,trapz(xfeld,wsumme/TORE,2))
%Wahrscheinlichkeit über das gesamte Feld. Sollte bei 1 liegen. Octave gibt den Wert 0.91 aus, was an der "abgeschnittenen" Funktion nahe der Torauslinie liegen könnte
W=trapz((1:1:7),trapz((1:1:11),torez/TORE,2))



Fazit und Verbesserungsvorschläge
[Bearbeiten]Im ersten Zyklus wurden Abhängigkeiten zwischen der Spielzeit und der Toranzahl gesucht, aber nicht gefunden. Es ist zwar eine leichte Tendenz dahingehend erkennbar, dass der FC Bayern München in den letzten fünf Minuten mehr Tore erzielt, als in den vorherigen Zeitintervallen. Jedoch wurden hier nur die Spiele einer Saison betrachtet. Eine größere Stichprobe könnte diese Tendenz entweder bestätigen oder widerlegen. Ebenso wäre an dieser Stelle auch ein Vergleich mit anderen Mannschaften interessant, um festzustellen, ob eine erhöhte Toranzahl in den letzten fünf Minuten auch bei anderen Mannschaften auffällig ist. Dass in den letzten Spielminuten mehr Tore fallen, als in den zuvorigen, könnte sich mit der, gegen Ende schwächelnden, Ausdauer erklären: Ein Nachlassen der Ausdauerleistungsfähigkeit hat einen Konzentrationsverlust zur Folge und kann somit Fehler produzieren, die im "worst case" einen Gegentreffer zur Folge haben. Im dritten Zyklus konnte mit Hilfe der Verteilungsfunktion letztendlich die Wahrscheinlichkeit eines Torerfolges bezüglich der Spielfeldposition ermittelt werden. Es muss festgehalten werden, dass in allen Zyklen nicht alle Zufallsvariablen berücksichtigt wurden, welche auch einen Einfluss auf die Wahrscheinlichkeiten haben. Eine Fußballmannschaft stellt sich auf diesem Leistungsniveau immer auf die gegnerische Mannschaft ein, d.h. bei einem Spiel gegen eine vermeintlich leistungsschwächere Mannschaft erfolgt eine andere taktische Einstellung, als bei einem Spiel gegen eine vermeintlich bessere Mannschaft. Eine Kategorisierung von Spielen gegen "schwächere" und "stärkere" Teams hätte eine Präzisierung sein können. Ebenso hätte auch die Belastungsintensität der Spiele, d.h. die Anzahl der Regenerations- und Trainingstage zwischen den Spielen betrachtet werden können. Folgen in einer bspw. englischen Woche, d.h. mehrere Spiele in einer kurzen Zeit hintereinander, so hat dies auch Auswirkungen auf die Spieltaktik und die Spielerrotationen, welche auch wiederrum möglicherweise einen Einfluss auf die Torerzielung haben. Eine Differenzierung nach Spielen mit "hoher" und "geringer" Belastungsintensität hätte hier eine weitere Präzisierung ermöglicht. Zudem hätten Sperren und Verletzungen verschiedene Spielerrotationen und Systemänderungen zur Folge.
Eine Betrachtung all dieser weiteren Faktoren hätte den Rahmen dieses Modellierungsprojektes gesprengt und konnten somit leider nicht berücksichtigt werden. Um nicht abhängig von so vielen Zufallsvariablen zu sein, wäre auch die Betrachtung der Torerzielung eines Spielers eine mögliche Option, um den Trainer der gegnerischen Mannschaft diesbezüglich Handlungsvarianten zu ermöglichen.
Zuordnung des Modellierungsthemas zu den Nachhaltigkeitszielen (Sustainable Development Goals)
[Bearbeiten]Auch der Sport hat einen Entwicklungsauftrag zur Nachhaltigkeit. Durch die Förderung von Werten wie beispielsweise Fairplay, Respekt, Gleichstellung und Toleranz wird ein Beitrag zur Stärkung der jungen Menschen, Frauen, "[...]des Einzelnen und der Gemeinschaft und zu den Zielen der Gesundheit, der Bildung und der sozialen Inklusion [...]" [1] geleistet.
Im Allgemeinen lassen sich folgende Nachhaltigkeitsziele der UN mit dem Sport - übergreifend für Fußball und andere Sportarten - verknüpfen.
- SDG 3: Good Health and Well-being
- SDG 5: Gender Equality
- SDG 16: Peace, Justice and Strong Institutions
- SDG 17: Partnerships for the Goals